Training the Untrainable: Introducing Inductive Bias via Representational Alignment
Abstract
We demonstrate that architectures which traditionally are considered to be ill-suited for a task can be trained using inductive biases from another architecture. We call a network untrainable when it overfits, underfits, or converges to poor results even when tuning their hyperparameters. For example, fully connected networks overfit on object recognition while deep convolutional networks without residual connections underfit. The traditional answer is to change the architecture to impose some inductive bias, although the nature of that bias is unknown. We introduce guidance, where a guide network steers a target network using a neural distance function. The target minimizes its task loss plus a layerwise representational similarity against the frozen guide. If the guide is trained, this transfers over the architectural prior and knowledge of the guide to the target. If the guide is untrained, this transfers over only part of the architectural prior of the guide. We show that guidance prevents FCN overfitting on ImageNet, narrows the vanilla RNN–Transformer gap, boosts plain CNNs toward ResNet accuracy, and aids Transformers on RNN-favored tasks. We further identify that guidance-driven initialization alone can mitigate FCN overfitting. Our method provides a mathematical tool to investigate priors and architectures, and in the long term, could automate architecture design.
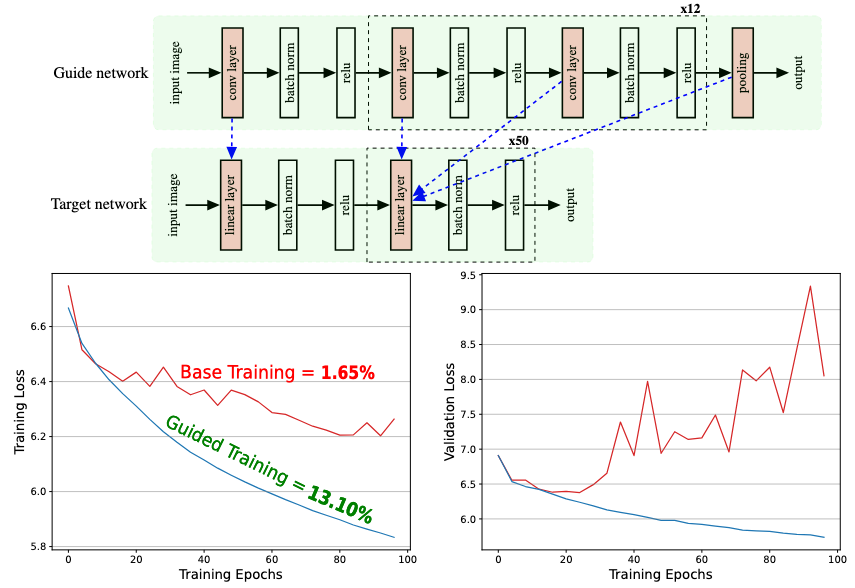
What is guidance?
We propose Guidance between two networks to make untrainable networks trainable. Given a target which cannot be trained effectively on a task, e.g., a fully connected network (FCN) which immediately overfits on vision tasks, we guide it with another network.
Layer-wise representational alignment In addition to the target's cross-entropy loss, we encourage the network to minimize the representational similarity between target and guide activations layer by layer. We measure the similarity using centered kernel alignment.
Randomly Initialized Guide Networks The guide can be untrained, i.e., randomly initialized. This procedure transfers the inductive biases from the architecture of the guide to the target. The guide is never updated.
Training improvement The target undergoing guidance no longer immediately overfits can now be be trained. Here we show an untrained ResNet guiding a deep fully connected network to perform object classification. The FCN alone overfits, the guided version can now be optimized. It has gone from untrainable to trainable.
Results: Guidance makes untrainable networks trainable!
Guidance improves performance for image classification across fully connected networks and deep convolutional networks without residual connections, particularly with randomly initialized guide networks.
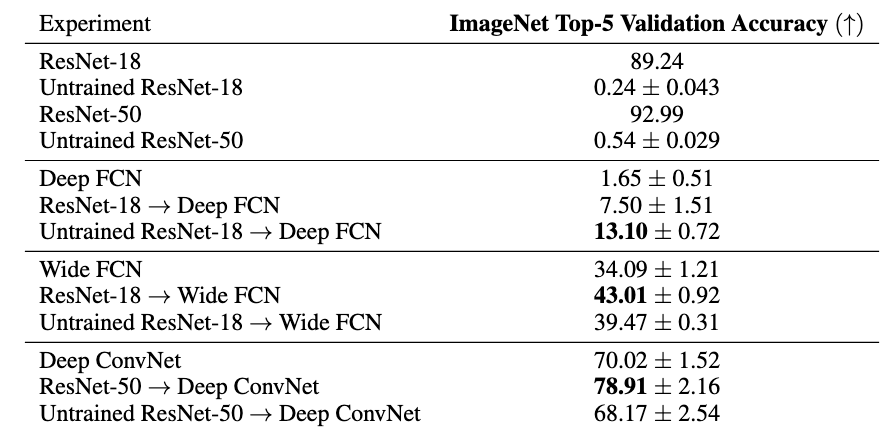
We apply guidance on three untrainable networks: (1) a Deep FCN guided by a ResNet-18, (2) a Wide FCN guided by a ResNet-18, and (3) a Deep Convolutional Network guided by ResNet-50. Across all settings, guidance can help train architectures that were otherwise considered unsuitable.
Guidance improves performance for sequence modeling across 3 tasks that are untrainable across both transformers and RNNs.

We apply guidance on across two sequence-based architectures for three sequence modeling tasks: (1) copy-paste with RNN guided by a Transformer, (2) parity with a Transformer guided by an RNN, and (3) language modeling with an RNN guided by a Transformer. RNN performance improves dramatically when aligning with the representations of a Transformer for copy and paste, as well as for language modeling. RNNs close most of the gap to Transformers for language modeling. Transformers in turn, improve parity performance when aligning with an RNN. Guidance is able to transfer priors between networks.
Guidance improves training by preventing overfitting and drives training and validation loss lower than using base training.
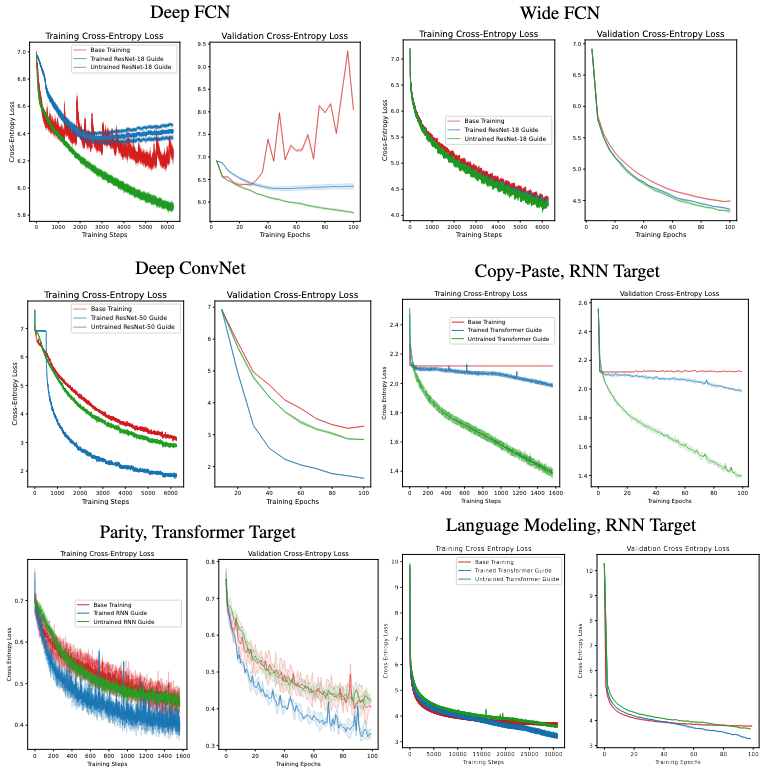
Training and Validation Curves We find across all settings that guidance improves training and validation loss. Guidance prevents overfitting and settings where loss saturates.
Error Consistency: Functional Properties of Guided Networks
Given our guided networks, we can analyze the functional properties of the guided network to confirm whether networks adopt priors from their guide networks. Using Deep FCN as our target model, we guide it with a ResNet-18 or a ViT-B-16. We then measure the error consistency between all of the networks.
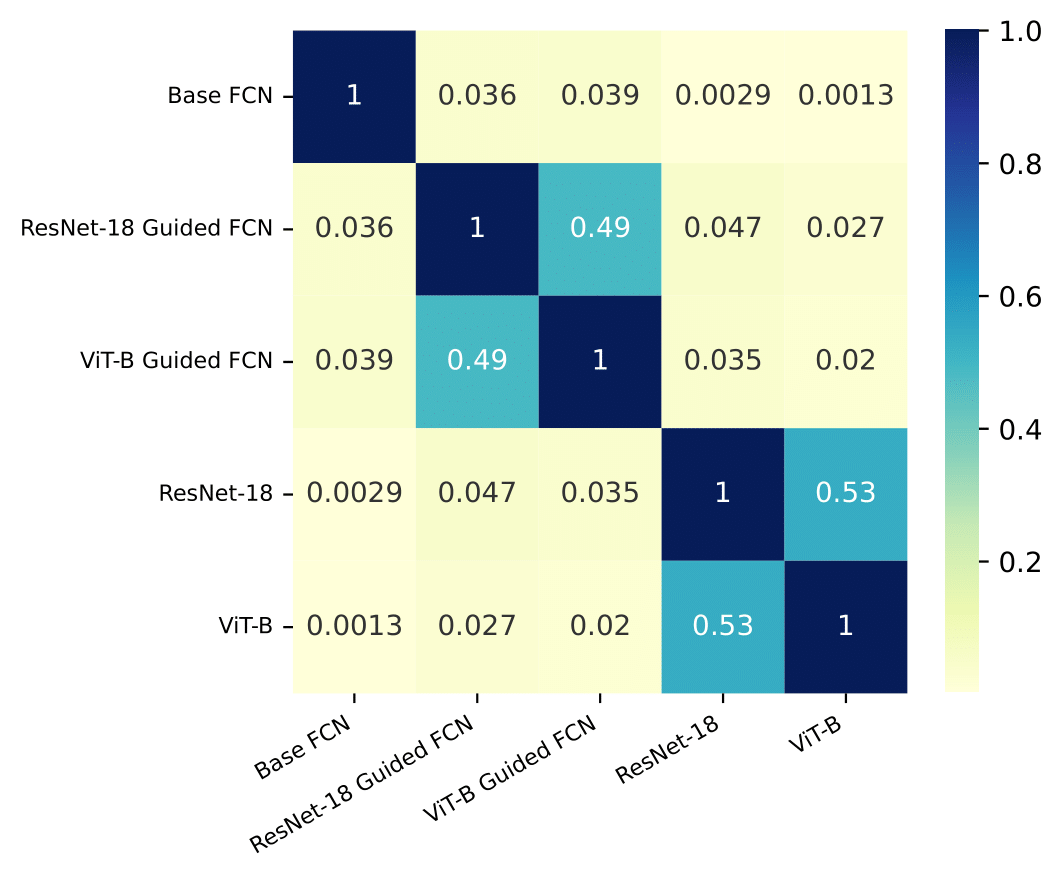
Guidance aligns error consistency. The relationship between the guide networks is mirrored in that
of the guided networks even when the target is entirely unlike the guides initially. This is additional evidence
that guidance doesn’t just improve performance arbitrarily, the target becomes more like the guide.
Guidance Implications for Network Initialization
Is guidance needed throughout training, or is the effect of the guide to move the target into a regime where the two are aligned and the target can be optimized further without reference to the guide? The answer to this question can shed light on whether the guide is telling us that better initializations are likely to exist for the target. To answer this question, we disconnect the guide from the target after an arbitrary and nominal number of training steps, 150.
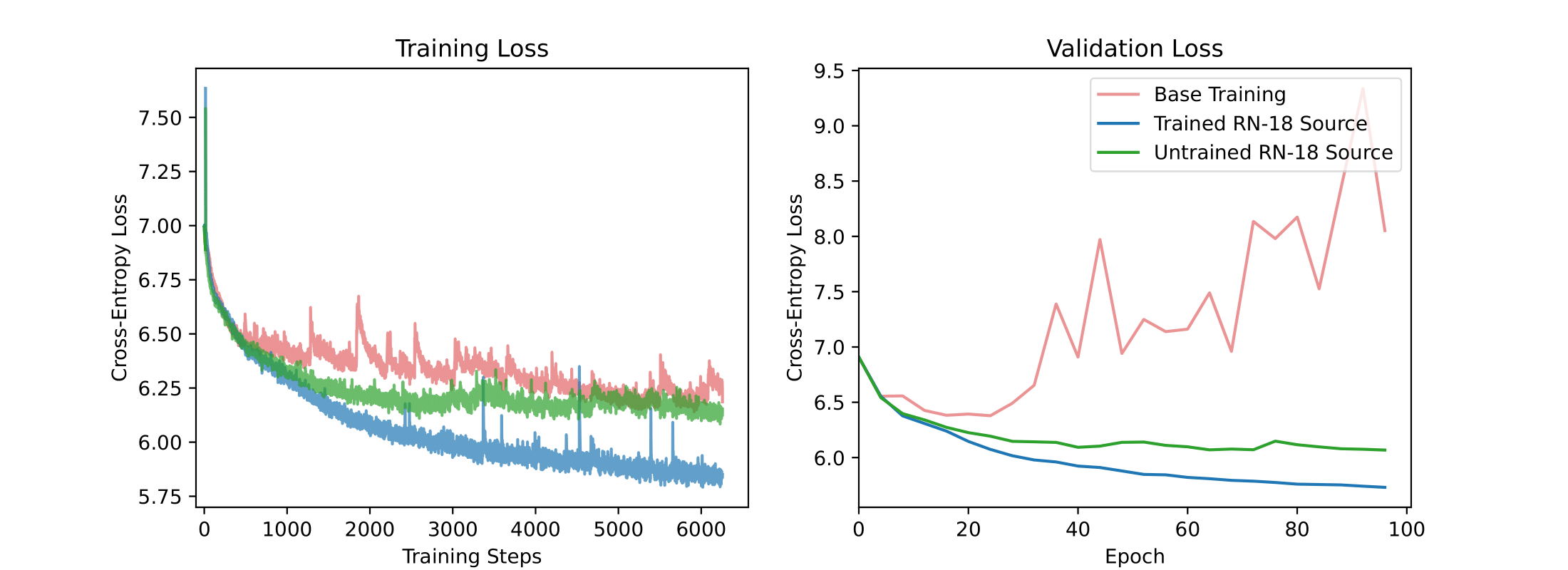
Disconnecting the guide early can have long-term effects. The Deep FCN
still does not diverge and the training and validation loss still mirror one another. Very likely, an initialization
regime exists for Deep FCNs that prevents overfitting. We now have the tools to investigate this question.